UCloud優刻得分鐘級創建千臺云主機技術解析
在數字化業務實踐中,某些客有些用戶的業務場景需要在短時間內能夠批量創建大量的云主機,這些典型業務場景包括:
1.芯片設計,由于單機無法滿足高計算需求,需要上百臺云主機完成眾多job的計算;
2.3D渲染,基礎鏡像大且需要大量云主機滿足不同渲染需求;
3.搶購類業務,需要大量云主機并發以提高搶購效率。創建云主機的速度關系到這些客戶的核心體驗。
在創建云主機過程中,最耗時的操作為克隆虛擬機鏡像這一步驟,需要將虛擬機鏡像從鏡像源復制一份到云盤集群。虛擬機鏡像包含虛擬機上的操作系統及用戶預裝的軟件,一個完整的鏡像數據量非常大,從幾GB到幾十GB不等,在實踐中,甚至有的鏡像數據達到幾百GB。創建N臺云主機意味著將鏡像數據復制分發N份,而且大部分公有云存儲都采用三副本技術進行數據冗余,這意味著復制分發的數據量還要放大三倍。因此,在大批量創建云主機場景下,復制分發海量數據需要用戶等待大量時間,這個時間往往是用戶業務無法接受的。
為了緩解用戶批量創建云盤主機耗時過長的問題,我們采用過鏡像預灌作為過渡方案,即提前為用戶克隆好系統盤鏡像。該方案存在明顯缺陷,不僅需要提前知曉客戶的熱門鏡像,超額預灌也會額外占用后端存儲資源。為了從根本上解決批量創建云盤主機耗時過長問題,我們設計了基于ROW(Redirect-On-Write)的克隆/快照技術,實現了寫時重定向的鏈式克隆,達到了秒級克隆的效果。
一、快照克隆技術選型

COW(Copy-On-Write) ,也被稱之寫時復制快照技術,這種方式通常也被稱為“元數據(源數據指針表)”拷貝。顧名思義,如果試圖改寫源數據塊上的原始數據,首先要將原始數據拷貝到新數據塊中,然后再進行改寫。當還原快照需要引用原始數據時,快照軟件會將原始數據原有的指針映射到新數據塊上。

ROW(Redirect-On-Write) ,也被稱之為寫時重定向。ROW的實現原理與COW非常相似,區別在于ROW對原始數據卷的首次寫操作,會將新數據重定向到預留的快照卷中,而非COW一般會使用新數據將原始數據覆蓋。所以,ROW快照中的原始數據依舊保留在源數據卷中,并且為了保證快照數據的完整性,在創建快照時,源數據卷狀態會由讀寫變成只讀的。如果對一個虛擬機做了多次快照,就產生了一個快照鏈,虛擬機的磁盤卷始終掛載在快照鏈的最末端,即虛擬機的寫操作全都會落盤到最末端的快照卷中。
該特征導致了一個問題,就是如果一共做了10次快照,那么在恢復到最新的快照點時,則需要通過合并10個快照卷來得到一個完整的最新快照點數據;如果是恢復到第8次快照時間點,那么就需要將前8次的快照卷合并成為一個完整的快照點數據。從這里可以看出ROW的主要缺點是沒有一個完整的快照卷,其快照之間的關系是鏈式的,如果快照層級越多,進行快照恢復時的系統開銷會比較大。但ROW的優勢在于其解決了COW快照寫兩次的問題,所以就寫性能而言,ROW無疑是優于COW的。
可以看出,ROW與COW最大的不同就是: COW的快照卷存放的是原始數據,而ROW的快照卷存放的是新數據。 因為ROW這種設定,所以其多個快照之間的關系必定是鏈式的,因為最新一次快照的原始數據很可能就存放在了上一次快照時創建的快照卷中。另外,對于分布式系統來說,由于數據分散分布在不同存儲節點上,進而提供了并發讀的機會,因此,在分布式存儲系統中,ROW的讀寫性能優于COW。
鑒于ROW與COW的對比優勢,以及UDisk自身分布式部署特點,我們最終采用基于ROW的方式實現內部快照,并對UDisk的整體架構進行改進優化。為了降低批量創建云盤主機時對鏡像存儲集群的壓力,引入Frigga模塊,管理UDisk內部鏡像,期望相同鏡像只從鏡像存儲集群拷貝一次,UDisk集群內部共享。
二、方案整體架構設計

Access: UDisk接入服務,接收外部請求,并下發請求到相應存儲集群中
Frigga: 鏡像分發管理模塊,管理從鏡像系統克隆的鏡像。全局部署,采用主備模式,對于鏡像集群中存儲鏡像的云盤提供新建、查詢等功能;
Metaserver: UDisk存儲集群元數據管理模塊,存儲管理集群快照克隆的鏈式關系和集群的路由信息;
Chunk: UDisk存儲集群后端數據存儲引擎,負責數據的實際讀寫
Client: 客戶端服務,UDisk存儲接入模塊,部署在宿主機上,負責虛機io下發到后端存儲集群
Ymer: 負責從鏡像系統拷貝鏡像到UDisk存儲集群
鏡像集群: 特殊的UDisk存儲集群,作為鏡像系統Cache,后端部署與普通集群一致。該集群只存儲基礎鏡像數據和克隆云盤數據,客戶批量創建云盤主機創建的云盤系統盤都會落在該集群中,后期通過遷移系統在線將云盤系統盤打散遷移到UDisk存儲集群中,遷移過程用戶無感知。該集群作為基礎鏡像緩存池,由Frigga模塊采用LRU策略淘汰冷鏡像數據,只存儲用戶的高頻熱點鏡像。
系統盤克隆整體流程
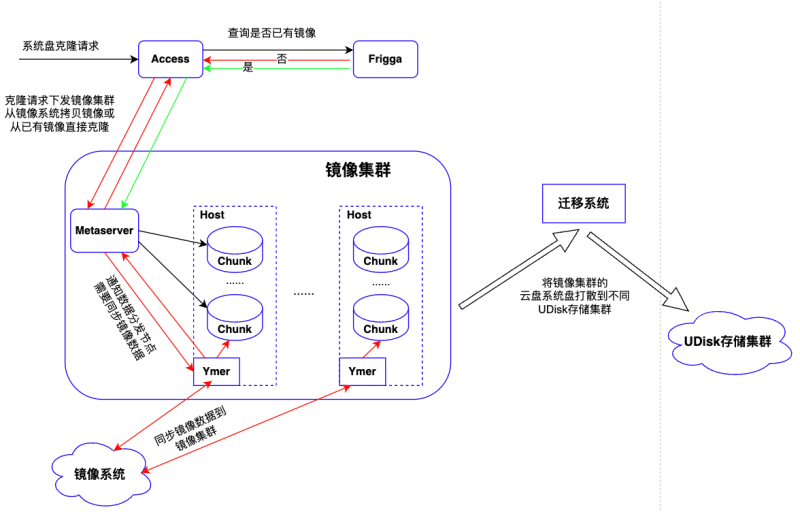
云主機服務下發系統盤克隆請求到Access接入服務,Access根據請求中的鏡像ID向Frigga查詢當前鏡像是否已存在后端鏡像集群。
若存在,則響應Access鏡像存在,同時返回鏡像對應云盤ID,Access根據云盤ID重新組織克隆請求,下發到鏡像集群Metaserver服務,Metaserver接收請求執行內部克隆,更新克隆盤與鏡像盤對應關系,并將關系信息同步給集群內所有Chunk服務,通知完成后向上層返回,克隆流程結束(上圖綠色線+黑色線部分)。整個過程不涉及與鏡像系統的交互,無數據拷貝,純內存操作, 毫秒級 時間內完成。
當請求的鏡像不存在時,Frigga本地內存新增鏡像記錄,并持久化DB。然后響應Access鏡像不存在,需要從鏡像系統克隆鏡像。Access接收響應后,向Metaserver下發從鏡像系統克隆請求,Metaserver創建鏡像云盤并通知Ymer從鏡像系統拷貝鏡像數據,通知成功后,向上層Access返回已開始克隆,Access接收到響應后再次向Metaserver下發從鏡像云盤的內部克隆請求,流程同上(上圖紅色線+黑色線部分)。不過此時鏡像尚未克隆完成,Frigga會不斷查詢鏡像云盤狀態,直到數據拷貝完成,此時系統盤可用。相較上面流程,多了一次從鏡像系統拷貝數據的過程,但也只需要一次拷貝,降低了對鏡像系統的負載壓力。
UDisk整體架構如何適配是核心問題,幾乎涉及到UDisk所有模塊的改動,下文將詳細介紹如何基于ROW實現內部快照/克隆的技術細節。
三、快照/克隆云盤實現原理
為了便于理解,先介紹幾個基本概念:1.UDisk提供塊存儲服務,對外可見的為一個個裸設備(云盤,也稱為邏輯盤,lc),每塊云盤對應一個全局唯一標識extern_id,每個extern_id會被分配到后端某個存儲集群,且在后端集群中為extern_id分配唯一id,即lc_id;2.每個Chunk服務管理一塊物理磁盤,底層以PC(4MB)為粒度管理整個物理磁盤的容量,并提供IO讀寫服務。
extern_id:云盤資源id,全局唯一
lc:邏輯盤,即云盤
lc_id:云盤在后端存儲集群內id,存儲集群內唯一
PC:邏輯存儲單元
Frigga鏡像管理
Frigga設計為主備模式,提高系統可用性。Frigga負責鏡像的導入,后端存儲集群鏡像管理以及克隆調度。與Ymer配合實現UDisk存儲集群間鏡像共享,從鏡像系統拷貝一次鏡像,UDisk存儲集群內數據共享,大大減輕鏡像系統負載。Frigga根據LRU策略管理本地鏡像,防止無效鏡像/冷鏡像占用存儲資源,當鏡像集群使用容量達到設定閾值時,根據LRU策略淘汰冷鏡像。
當鏡像集群容量到達使用閾值后,會根據LRU策略主動刪除長時間未使用鏡像。為防止單鏡像集群內從單一鏡像克隆過多云盤引起的訪問熱點問題,Frigga為每個鏡像集群內的鏡像設置單鏡像最大支持克隆盤數量閾值,當克隆盤數量超過設定閾值后,會重新從鏡像系統重新拷貝鏡像。
Metaserver元數據以及路由管理
UDisk原有架構設計中邏輯盤之間相互獨立,無相互關聯。為了實現UDisk存儲集群內部鏡像共享(鏡像在鏡像集群中也以邏輯盤存在),以邏輯盤lc粒度管理鏡像/快照/克隆盤關系,通過維護邏輯盤之間的關系實現快照的創建/克隆等操作,邏輯盤間的對應關系由Metaserver統一管理,并同步給Chunk以及Client服務。對盤多次打快照后,從不同快照克隆云盤后,Metaserver側維護的邏輯盤之間的拓撲結構如下圖所示:
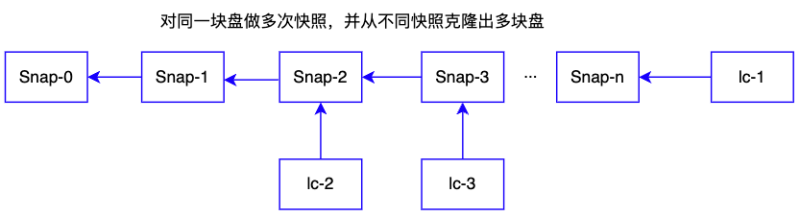
從同一鏡像批量克隆出多塊克隆盤后,邏輯盤之間的拓撲結構如下,所有克隆盤均指向鏡像云盤,只需要鏡像盤從鏡像系統拷貝一次,其他克隆盤的創建均為內存操作,Metaserver只需維護克隆盤到鏡像之間的映射關系即可,這樣極大提高了系統盤的克隆速度。
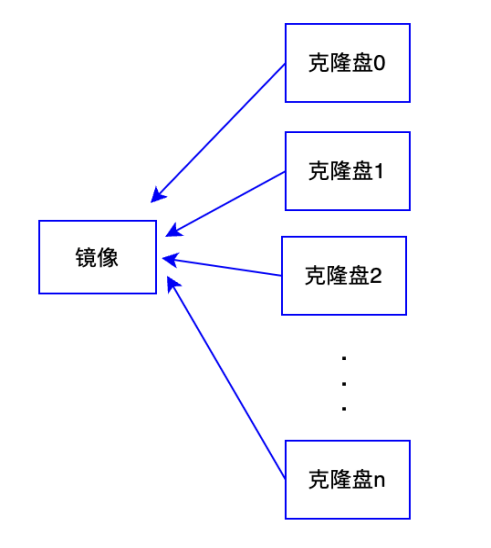
邏輯盤間的關系在Metaserver內存中都是一條條的鏈,鏈上的各邏輯盤都依賴其上層節點,從鏈的末尾節點可依次向上層查詢直到根節點。Metaserver會將邏輯盤之間的映射關系信息實時同步給Client以及Chunk服務,Client和Chunk服務與Metaserver之間也保持心跳消息,通過心跳主動同步邏輯盤映射關系信息,防止網絡分區導致的信息不一致。Metaserver通過version機制管理映射關系變化,通過比對Metaserver與Client/Chunk的version確定是否需要同步最新映射關系。
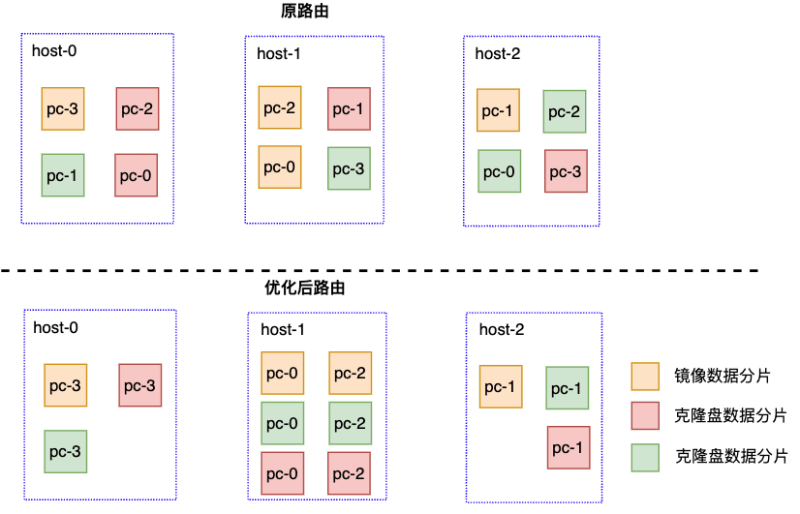
按照UDisk分布式設計原則,鏡像數據被分散存儲在鏡像集群不同物理主機上,按原有路由策略,克隆盤讀取鏡像數據時,可能會存在跨機器訪問的問題,增加數據讀取時延,影響云主機啟動速度。為此,我們優化了路由策略:克隆盤和鏡像擁有相同的路由信息,克隆盤和鏡像數據由相同的Chunk服務管理。這樣,當云主機啟動加載系統盤數據時,可以直接讀取對應Chunk上的鏡像數據,本地讀操作,減少網絡訪問時延。
Client IO下發
Client作為UDisk存儲集群的接入服務,負責將虛機的IO下發到存儲集群不同的Chunk服務上,為了保證將克隆盤的IO下發到對應鏡像所在Chunk服務上,Client側需要獲取對應克隆盤的所有映射關系,從而獲取到鏡像信息,以鏡像的路由策略下發IO。
Chunk側IO讀/寫流程優化
Chunk以PC為粒度管理磁盤,并處理IO,只有寫IO時Chunk才可能分配新PC。Chunk除了從Metaserver同步邏輯盤之間的映射關系外,還維護自身管理的PC信息。對lc多次做快照后,Chunk維護的PC間拓撲結構如下圖:

從同一鏡像克隆出多塊盤后,Chunk維護的PC間拓撲結構如下:
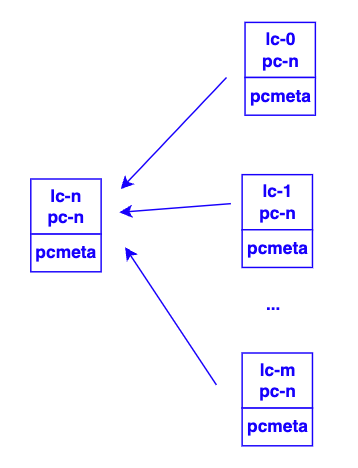
Chunk接收Client IO按照PC讀寫磁盤,每個PC對應一個pcmeta元數據,該元數據記錄了PC云盤與物理盤的映射關系,其中重定向標記位(bitmap)表示該數據是否需要從父節點讀取數據;每個標記位代表256k數據重定向結果,對于新建的克隆盤PC初始化時所有的bitmap都是1,表示每個256k都需要重定向讀寫。Client下發的IO可以由一個四元組PC Entry(lc_id, pc_no, offset, length)表示,代表要讀寫的邏輯盤、讀寫位置所屬PC、PC內位置、讀寫大小以及數據。
讀io重定向
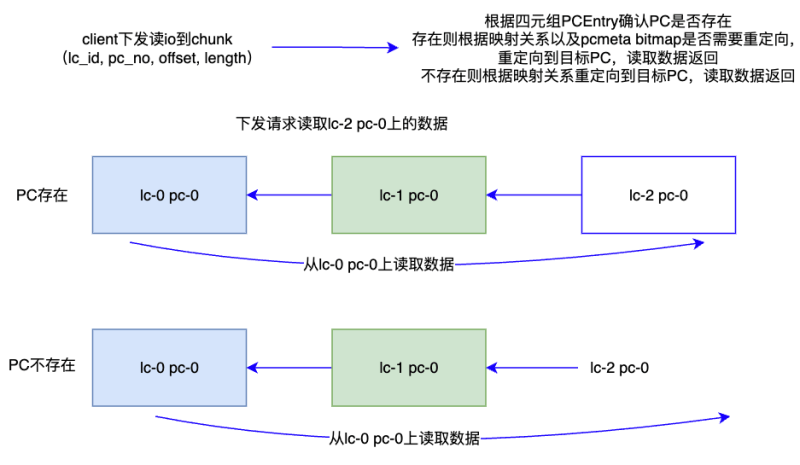
對于讀請求,首先根據四元組PC Entry確認PC是否存在,若存在,再根據pcmeta中bitmap對應位是否為1確認是否需要重定向讀,bitmap為0說明讀取的數據在當前PC上,直接讀取數據即可。發現對應的bitmap為1就尋找父節點繼續判斷標記位,直到父節點的標記位為0表示不需要重定向直接讀取父節點PC對應位置的數據。
寫io重定向
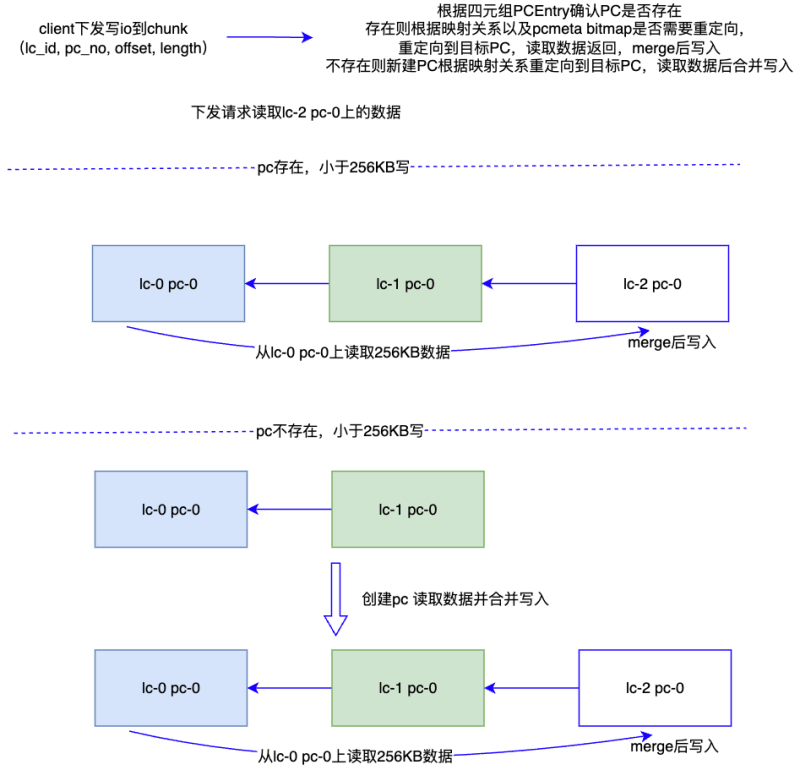
對于寫io判斷首先判斷PC是否存在,如果克隆的PC存在,再判斷bitmap是否為1(需要重定向),如果為1就會找父節點對應的PC,先將父節點對應PC的256k數據讀取出來,再與當前寫io數據做合并,再寫入對應的磁盤。如果克隆的PC不存在,則先創建PC,創建PC的pcmeta中bitmap設置為1,再按照之前PC存在的流程同樣處理io。
四、總結
為了能夠達到秒級克隆的效果,達到短時間創建大批量虛機的需求,我們采用了ROW的方法,同時利用了鏡像緩存池作為熱點鏡像數據,提高了基礎鏡像克隆與內部克隆的速度與效率,能夠達到5min內批量創建1000以上虛機的要求。
目前,該方案已在海外洛杉磯、新加坡機房全量開放,國內上海、廣州、北京、香港等機房已針對特定客戶開放。主要目標客戶為短時間內有批量創建虛機需求或者大容量基礎鏡像的客戶,可以大大縮短用戶創建虛機時間。目前,可支撐用戶業務高峰期批量2500臺虛機的創建需求。






